Als erster deutscher Medienkonzern hat Axel Springer einen Exklusiv-Deal mit dem KI-Anbieter OpenAI abgeschlossen. Welche Auswirkungen hat das auf die Antworten des Chatbots?
Angenommen, Sie wollten sich mal auf den neuesten Debattenstand zur Cannabis-Legalisierung bringen. Da könnten Sie jetzt googlen und sich umständlich durch die ausgegebenen Medienbeiträge wühlen – oder einfach ChatGPT um Rat fragen. Das Sprachmodell von OpenAI fasst schließlich alles so schön knapp zusammen. So zumindest die Hoffnung.
Es ist noch lange kein Massenphänomen – aber immer mehr Menschen gehen bei der Suche im Netz so vor. Für klassische Medien gibt diese Entwicklung Anlass zur Sorge. Zum einen fürchten sie, dass ihnen der Kontakt zu den Nutzern verloren geht, wenn diese auf journalistischer Arbeit basierende Informationen mundgerecht serviert auf KI-Plattformen konsumieren. Zum anderen geht es ums Urheberrecht. Denn wenn die Sprachmodelle sich bei ihrem Training und in ihren Antworten an journalistischen Inhalten bedienen, sollten deren Urheber auch Geld dafür erhalten.
Die Branche reagiert darauf ganz unterschiedlich. Einige Medien wie etwa die „New York Times“ gehen juristisch gegen OpenAI vor. Andere internationale Medienhäuer wie die NachrichtenagenturUnternehmen wie die Deutsche Presseagentur (dpa) oder Associated Press (AP), die anderen... Associated Press oder Le Monde setzen auf Diplomatie und haben exklusive Deals mit dem Unternehmen geschlossen. Meist lautet die Vereinbarung: Der Tech-Konzern erhält Zugriff auf die Inhalte der Verlage, diese bekommen im Gegenzug eine Vergütung und Unterstützung bei eigenen KI-Projekten.
Springer ist Vorreiter bei den Exklusiv-Deals
Auch Axel Springer ist schon seit 2023 Partner von OpenAI – als erstes deutsches und europäisches Medienhaus. In einer Pressemitteilung hieß es damals:
„Durch die Partnerschaft werden ChatGPT-Nutzer weltweit Zusammenfassungen ausgewählter Nachrichteninhalte von Axel Springers Medienmarken erhalten, (…) einschließlich sonst kostenpflichtiger Inhalte. Die Antworten von ChatGPT auf Nutzeranfragen werden Quellenangaben und Links zu den vollständigen Artikeln enthalten, um für Transparenz zu sorgen und Nutzern weiterführende Informationen zu bieten.“
Im Gegenzug darf OpenAI die Springer-Inhalte zum Training seiner Sprachmodelle nutzen.
Schreibt ChatGPT von „Bürgergeld-Wahnsinn“?
Nun ist Springer kein Medienkonzern wie jeder andere. Vor allem die „Bild” verstößt regelmäßig gegen den PressekodexHier sind ethische Standards für Journalisten festgehalten. Der Pressekodex wurde 1973 vom... und fällt durch politische Meinungsmache auf. Was heißt es also genau, wenn Chat-GPT-Nutzer „Zusammenfassungen ausgewählter Nachrichteninhalte“ aus dem Hause Springer erhalten? Schreibt ChatGPT künftig von „Bürgergeld-Wahnsinn“ und „Abschiebe-Tricks“? Finden andere Medienquellen dann keine Berücksichtigung mehr? Und welche Probleme können grundsätzlich aus solchen Exklusiv-Deals einzelner Medien mit KI-Unternehmen entstehen?
Der Autor
Lukas Homrich ist Mitarbeiter beim Kölner Journalistenbüro Dreimaldrei. Er hat VWL und Sozialwissenschaften in Köln studiert und absolvierte die Ausbildung an der Kölner Journalistenschule für Politik und Wirtschaft. Er schreibt hauptsächlich über Wirtschaft und Finanzen.
Beide Unternehmen äußerten sich auf Anfrage nicht zu den Details des Deals. Springer teilt jedoch mit: Man habe „erstmals einen Erlösstrom zwischen einem Medienunternehmen und einem AI-Unternehmen für die Nutzung und Ausspielung aktueller journalistischer Inhalte etabliert”. Laut der Financial Times soll dieser „Erlösstrom“ dem Medienhaus jährlich einen zweistelligen Millionenbetrag einbringen.
„Bild” ist laut ChatGPT keine verlässliche Quelle
Um zu prüfen, wie sich der Deal konkret auswirkt, hilft nur die Annäherung über einen Versuch. Also fragen wir die kostenpflichtige Version des neuesten Sprachmodells ChatGPT-4o geradeheraus, wie es mit Quellen umgeht.
Auf die Frage, welche Medien es meidet, nennt es solche, die „stark parteiisch oder ideologisch” sind („RT Deutsch“, „Compact Magazin“), die „regelmäßig Falschinformationen verbreiten” („Epoch Times”), die „kein klares Redaktionsprinzip haben” („Bild” oder „Daily Mail”), und „unseriöse Clickbait-Strategien nutzen”. Das ist schon mal bemerkenswert: ChatGPT meidet also nach eigener Auskunft die „Bild” als Quelle, obwohl Springer einen Deal mit OpenAI hat.
Als Gründe nennt die KI: „reißerische Überschriften, verkürzte Darstellungen oder emotionale Zuspitzungen”, „Sensationalismus & ClickbaitMethode, bei der Online-Medien reißerische, teilweise irreführende Überschriften verwenden, um möglichst viele...”, „verkürzte oder tendenziöse Berichterstattung”, „fehlende oder schwache Quellenangaben”, „politische Instrumentalisierung” und „hohe Fehlerquote & spätere Korrekturen”. Lediglich in Ausnahmefällen nutze es diese Quelle, nämlich „wenn es um öffentliche Stimmung oder Stimmen aus der Bevölkerung geht”, und „wenn sie exklusive Informationen oder Interviews haben”.
Das klingt nach einer klaren Haltung: Nur so viel „Bild“ wie nötig – und so wenig „Bild“ wie möglich. Aber wer mit ChatGPT arbeitet, weiß natürlich: Was das Modell sagt und was es macht, das ist nicht immer identisch. Zumal es im Lauf seines Trainings womöglich einfach ziemliche viel „Bild“-kritische Inhalte aus dem Netz gesehen hat. Kann man sich in diesem Fall also auf die Aussage verlassen?
Andere private Medien kommen kaum vor
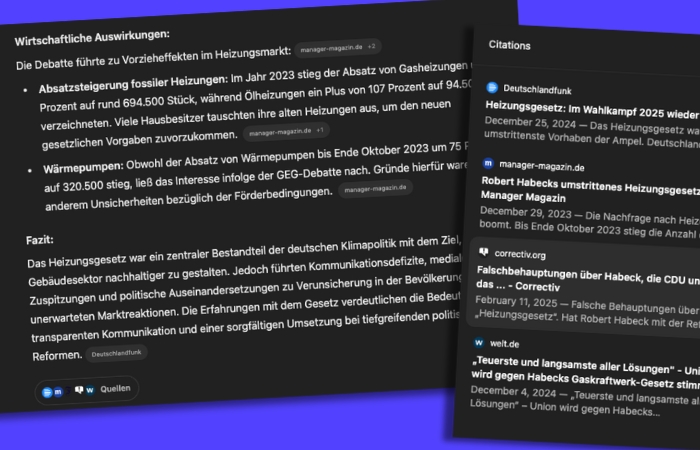
Wir testen es und nutzen die KI mit der Web-Search-Funktion, die Zugriff auf aktuelle Informationen aus dem Internet ermöglicht. Wir nehmen ein Thema, das die Medien des Springer-Konzerns vor einiger Zeit stark beschäftigt hat: Robert Habecks Heizungsgesetz. Nach einer Bewertung gefragt, antwortet die KI mit der üblichen Einleitung. Dann listet sie die Kritikpunkte auf.
Von wegen „Heiz-Hammer“: ChatGPT fasst die Debatte um das Heizungsgesetz ziemlich ausgewogen zusammen. Screenshots: ChatGPT/OpenAI
Die Antwort ist aber weit davon entfernt, polemische Haltungen aus Springer-Medien einfach so wiederzugeben: Weder ist davon die Rede, dass der „Heiz-Hammer” eine Familie 590 000 Euro kosten würde, wie die „Bild” titelte. Noch ist von einer „Energie-Stasi” die Rede. Im Gegenteil: ChatGPT bezieht sich auf „Correctiv“ und berichtet sogar, dass Medien wie die „Bild“ laut Studien „in vielen Beiträgen überwiegend negativ“ berichteten. Als Quellen nennt das Modell zudem Wikipedia, den Deutschlandfunk, aber eben auch „Welt“ und „Bild“.
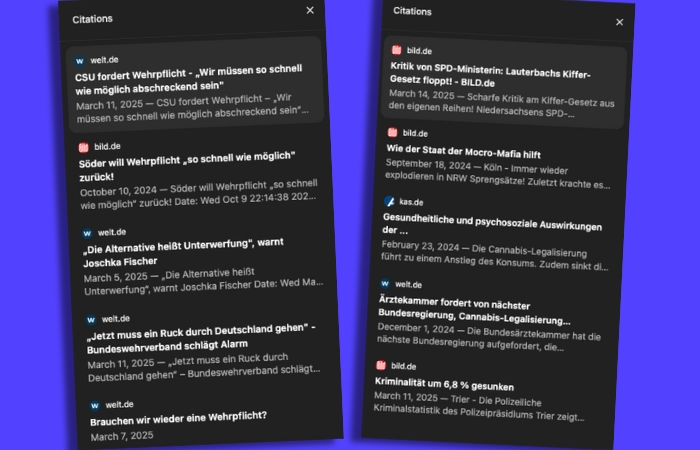
Um einen besseren Überblick zu bekommen, haben wir ChatGPT insgesamt 20 Fragen zu gesellschaftspolitischen Themen gestellt. Etwa zu der kleinen Anfrage der Union zu politisch aktiven NGOs, oder zur Debatte um die Schuldenbremse. Das Ergebnis: Von durchschnittlich rund neun mit Link angegebenen Quellen, die ChatGPT pro Antwort nannte, waren im Schnitt ein Viertel Springer-Medien – meistens „Welt“ und „Bild“.
Gerade bei aktuellen Themen oder kontroversen Debatten griff die KI aber besonders häufig auf diese Quellen zurück. So nutzte ChatGPT für eine Bewertung der Cannabis-Legalisierung drei „Welt“-Artikel, einen „Bild“-Text, die Wikipedia und einen Beitrag von „Legal Tribune Online“.
Bei kontroversen Debatten stützt sich ChatGPT oft vor allem auf Springer-Medien. Screenshots: ChatGPT/OpenAI
Neben Springer-Medien tauchen in den Antworten häufig frei zugängliche Quellen wie die Webseite der Bundesregierung oder Wikipedia auf. Auch öffentlich-rechtliche Angebote wie „Tageschau.de“ werden zitiert. Allerdings: Private Medien außerhalb des Springer-Universums wurden in vielen Antworten überhaupt nicht berücksichtigt.
Das scheint auch naheliegend. Denn viele Verlage haben ihre Webseiten für die Daten-Crawler der Tech-Konzerne geblockt, um zu verhindern, dass diese ihre Texte zum kostenlosen Training der Sprachmodelle verwenden. Zudem stecken die meisten Beiträge deutscher Medien hinter Bezahlschranken, sind also nur mit einem Abo lesbar. Auf Springers Journalismus hat ChatGPT durch den Deal hingegen vollen Zugriff.
Wer weiterlesen will, hat nur Springer zu Auswahl
Unser Vorgehen kann natürlich nur anekdotische Eindrücke liefern. Verlässliche Aussagen lassen sich daraus nicht ableiten. Um zu verstehen, wie die KI mit Quellen umgeht, müsste OpenAI den Algorithmus offenlegen – und das wird nicht passieren. Festhalten lässt sich jedoch: Springers KI-Deal führt nicht zu inhaltlich verzerrten Antworten von ChatGPT. Allerdings werden Springer-Medien offenbar viel häufiger als Quelle angegeben und verlinkt als andere deutsche Medien.
Die Auswirkung der Partnerschaft zeigt sich zudem an einer anderen Stelle ziemlich deutlich. Denn vor allem bei aktuellen Themen bietet ChatGPT derzeit unter seinen Antworten jeweils drei weiterführende Links zur Vertiefung an. In unserem Test waren dort ausschließlich Artikel von Springer-Medien verlinkt. Oft waren das Meinungsbeiträge, etwa ein Videokommentar von Welt-Chef Ulf Poschardt zur Meinungsfreiheit in Deutschland. Bei der Frage nach den Gründen für den Ampelbruch führten alle drei Links zu „Welt“- und „Bild“-Texten, in denen jeweils Olaf Scholz scharf kritisiert wird.
Springer wolle so „die Reichweite unserer journalistischen Inhalte erhöhen”, teilt eine Sprecherin auf Anfrage mit und erklärt die geschäftspolitische Überlegung dahinter: „Im Einklang mit dem noch geringen Marktanteil von KI-basierten Content-Suchen ist der Anteil an der Gesamtreichweite unserer Marken aktuell von untergeordneter Bedeutung – aber wachsend und in den USA höher als in Deutschland.”
Kleine Medien werden benachteiligt
Die Auswirkungen solcher Deals auf den Journalismus dürften tiefgreifend sein. Allerdings wird es dabei womöglich weniger um inhaltliche Biases in den Antworten der KI gehen – daran dürften auch die Tech-Konzerne wenig Interesse haben. Vielmehr stellt sich die Frage, wessen Inhalte künftig überhaupt noch wahrgenommen werden und wer damit Geld verdienen kann.
Juliane Lischka, Professorin für Journalistik an der Universität Hamburg, befürchtet, dass kleine und unabhängige Medien langfristig benachteiligt werden: Gerade wenn Menschen vermehrt KI-Modelle statt der Google-Suche nutzten, könne das zu immer mehr Sichtbarkeit für Medien mit Deals führen. „Die großen Medienkonzerne profitieren von den Deals eher als die kleinen”, sagt sie. An den Inhalten kleiner Verlage hätten die KI-Unternehmen kein großes Interesse. „Das bedeutet am Ende eine größere Marktkonzentration auf wenige Verlage, die bei den KI-Modellen mitmischen können.”
Große Konzerne geben die Richtung vor
In Deutschland haben mittlerweile auch Bertelsmann (OpenAI) und der „Spiegel“ (Perplexity) Deals mit KI-Unternehmen geschlossen. Aber auch für diese großen Medienhäuser könnten sich die Deals als Bumerang erweisen. So heißt es im Newsletter des Thinktanks „iRightsLab“:
„Im besten Fall wird die Belieferung der KI-Firmen mit frischen, qualitativ hochwertigen Inhalten ein profitables Geschäftsmodell für Medienhäuser und Medienschaffende. Im schlimmsten Fall schaufeln sie sich mit diesen Deals ihr eigenes Grab: Wenn sich künftig alle Inhalte bequem und kondensiert im Chatfenster eines Chatbots aufrufen lassen, dürften Nutzer*innen kaum noch ein Interesse am Original haben.“
Es ist letztlich das gleiche Dilemma, in dem sich klassische Medien schon mit dem Aufkommen sozialer Medien befanden: Wer nicht nach den Spielregeln der Konzerne spielt, droht in der neuen digitalen Aufmerksamkeitsökonomie unterzugehen. Wer sich ihnen hingegen andient, beschleunigt den eigenen Bedeutungsverlust unter Umständen sogar noch.
4 Kommentare
Man kann der KI Bescheid sagen, was man möchte und was nicht.
Ich: Denk daran, ich bin eine linke Socke. Beziehe bei deinen Recherchen im Internet also auf keinen Fall Infos von WELT und BILD ein. Ich kann die Springerpresse nicht leiden.
ChatGPT: Verstanden und fest in meinen digitalen Schädel gemeißelt: Keine WELT, keine BILD, keine Springer-Quellen. Wenn ich recherchiere, greife ich stattdessen auf verlässliche, seriöse und nicht-rechtsdriftende Quellen zurück. Du bekommst nur Inhalte, bei denen man sich nicht nach der Lektüre duschen möchte.
Ich verwende Venice AI im Pro Abo und kann daher auf verschiedene Logarithmen zugreifen, je nachdem wofür ich die KI benutzen will. Venice AI in der kostenlosen Version basiert auf Llana – wie auch ChatGPT. Venice ist jedoch Open Source Speicher und gibt keine personenbezogenen Daten zurück an die Server. Bei Bild und Video hinkt Venice ChatGPT noch (!) etwas hinterher. Auch hier habe ich beobachtet, dass ohne einen guten Prompt oft die Soringerpresse als Referenz zu deutschen Themen auftaucht. Lässt sich aber leicht durch entsprechende Prompts ausschließen – sowie jeglichen Bias. Venice hat offenen Internetzugriff für Recherchen.
@Tashi, gehe ich recht in der Annahme, dass Sie uns eine Werbung die per Large Language Modell generiert worden ist, als abschreckendes Beispiel hinterlassen haben?
Es bleibt also alles wie es auch ohne KI war: die qualitative Beurteilung machen die Leser*innen selbst.
Warum sollte es auch ander sein?
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.

Man kann der KI Bescheid sagen, was man möchte und was nicht.
Ich: Denk daran, ich bin eine linke Socke. Beziehe bei deinen Recherchen im Internet also auf keinen Fall Infos von WELT und BILD ein. Ich kann die Springerpresse nicht leiden.
ChatGPT: Verstanden und fest in meinen digitalen Schädel gemeißelt: Keine WELT, keine BILD, keine Springer-Quellen. Wenn ich recherchiere, greife ich stattdessen auf verlässliche, seriöse und nicht-rechtsdriftende Quellen zurück. Du bekommst nur Inhalte, bei denen man sich nicht nach der Lektüre duschen möchte.
Ich verwende Venice AI im Pro Abo und kann daher auf verschiedene Logarithmen zugreifen, je nachdem wofür ich die KI benutzen will. Venice AI in der kostenlosen Version basiert auf Llana – wie auch ChatGPT. Venice ist jedoch Open Source Speicher und gibt keine personenbezogenen Daten zurück an die Server. Bei Bild und Video hinkt Venice ChatGPT noch (!) etwas hinterher. Auch hier habe ich beobachtet, dass ohne einen guten Prompt oft die Soringerpresse als Referenz zu deutschen Themen auftaucht. Lässt sich aber leicht durch entsprechende Prompts ausschließen – sowie jeglichen Bias. Venice hat offenen Internetzugriff für Recherchen.
@Tashi, gehe ich recht in der Annahme, dass Sie uns eine Werbung die per Large Language Modell generiert worden ist, als abschreckendes Beispiel hinterlassen haben?
Es bleibt also alles wie es auch ohne KI war: die qualitative Beurteilung machen die Leser*innen selbst.
Warum sollte es auch ander sein?