Wahlumfragen beeinflussen Wahlen. Der INSA-Chef sagt: Das ist auch gut so.
Die CDU hat die Landtagswahl in Sachsen-Anhalt mit riesigem Vorsprung gewonnen. Dabei hatten insbesondere die Umfragen von INSA ein Kopf-an-Kopf-Rennen mit der AfD erwarten lassen. Was ist da schief gelaufen?
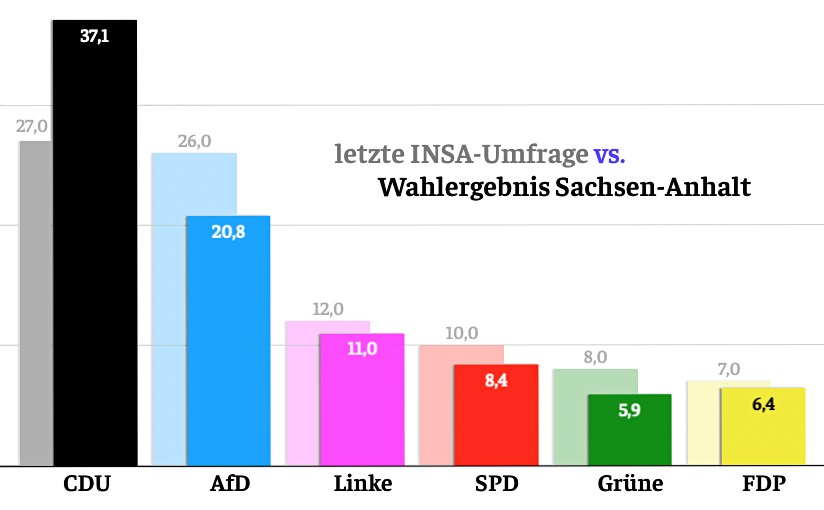
Die CDU hat die Landtagswahl in Sachsen-Anhalt mit 37,1 Prozent der Stimmen und über 16 Prozentpunkten Vorsprung vor der AfD gewonnen. Das war eine Überraschung. Meinungsforscher hatten einen viel geringeren Abstand erwartet; beim Meinungsforschungsinstitut INSA lag vor zwei Wochen sogar die AfD vorne.
Das prägte auch die Berichterstattung vieler Medien, die ein Kopf-an-Kopf-Rennen vorhersagten. Gerade das könnte dazu geführt zu haben, dass dieser Fall nicht eintrat und viele Anhänger anderer Parteien der CDU ihre Stimme gaben, um einen Wahlsieg der AfD zu verhindern.
Umfragen
CDU
AfD
Linke
SPD
Grüne
FDP
INSA, 26.5.
25,0
26,0
13,0
10,0
11,0
8,0
Infratest, 27.5.
28,0
24,0
10,0
11,0
9,0
8,0
FG Wahlen, 28.5.
29,0
23,0
11,0
10,0
9,0
8,0
FG Wahlen, 3.6.
30,0
23,0
11,5
10,0
9,0
6,5
INSA, 4.6.
27,0
26,0
12,0
10,0
8,0
7,0
Wahlergebnis, 6.6.
37,1
20,8
11,0
8,4
5,9
6,4
Meinungsumfragen mit Datum der Veröffentlichung. Quelle: wahlrecht.de
Ein Gespräch mit Hermann Binkert, Geschäftsführer des Marktforschungsinstituts INSA-Consulere, über Meinungsumfragen und ihre möglichen dramatischen Folgen auf das Wahlverhalten.
Foto: Imago
Herr Binkert, wie erklären Sie, dass die INSA-Umfragen soweit vom tatsächlichen Ergebnis abwichen? Waren die Umfragen falsch oder gab es nach den Umfragen einen massiven Meinungsumschwung?
Binkert: Wir machen das nach allen Regeln der Kunst, das war ja nicht die erste Umfrage zu Landtages- oder Bundestagswahlen, die wir gemacht haben. Wir messen die Stimmung zum Zeitpunkt der Erhebung. Jetzt können Sie natürlich sagen: Hätte man nach den Erfahrungen in Brandenburg, in Sachsen und in Thüringen nicht wissen müssen, dass die Partei des Ministerpräsidenten am Ende noch deutlich besser abscheiden wird? Aber dann würde ich ja eine Prognose machen, dann würde ich selber in unseren ermittelten Zahlen herumpfuschen. Das machen wir nicht.
Ich hielte es auch für gefährlich, das zu tun. Man wäre am Ende vielleicht im ein oder anderen Fall näher am tatsächlichen Wahlergebnis dran, aber das wäre dann geschätzt und nicht gemessen. Außerdem hatten wir seitdem die Corona-Pandemie, angekündigte Kanzlerkandidaten und einen laufenden Bundestagswahlkampf. Die politische Lage und die gemessene Stimmung sind aktuell sehr beweglich.
Aber müssen Sie das Rohmaterial nicht ohnehin im Nachhinein noch bearbeiten? Es gibt ja Effekte, die die Wahlforscher nach und nach erst erkannten – zum Beispiel, dass AfD-Wähler ihre Wahlabsicht nicht unbedingt offen äußern oder an solchen Umfragen gar nicht erst teilnehmen.
Wir haben dafür eine Rückerinnerungsfrage drin, in der wir fragen, was die Befragten beim letzten Mal gewählt haben. Damit können wir gewichten. Wir haben es auch bei der Bundestagswahl gesehen, dass die Messung funktioniert – da waren wir am nächsten von allen Instituten am Ergebnis dran. Ich glaube wirklich, dass es in Sachsen-Anhalt eine Sondersituation war.
Ich kann das an einem Bild vielleicht so erklären: Jeder hat seine Lieblingsfußballmannschaft. Aber wenn es ins Finale geht und darum, dass nur zwei Mannschaften siegen können, dann stellen sich auch die Fans anderer Mannschaften hinter eine, die noch die Chance hat, siegen zu können. Und das war halt die Union. Das führte zu einer Auseinandersetzung zwischen Union und AfD, die dann dazu führte, dass auch potentielle Wähler der Linken, der Grünen, der SPD und der FDP sagten: Diesmal wähle ich die CDU, um zu verhindern, dass die AfD stärkste Kraft wird.
Tweet für später: Es ist schon Wahnsinn, wie sehr diese eine INSA-Umfrage, die die AfD in #SachsenAnhalt vorn sah womöglich a) danebenliegen könnte und b) die Wahl zugunsten der CDU beeinflußt. #ltw21
Welchen Effekt kann in einer solchen Situation eine Umfrage auf das Wahlverhalten der Menschen haben? Angenommen, es hätte nur die Umfragen von Infratest Dimap und der Forschungsgruppe Wahlen gegeben, die ja anders als Sie kein so enges Rennen vorhergesagt haben – könnte es sein, dass es dann ein deutlich anders Ergebnis gegeben hätte?
Auch bei den anderen Instituten gab es ja immer die Erzählung eines Kopf-an-Kopf-Rennens. Das war ja nicht nur bei uns so. Ich glaube, wenn wir gemessen und veröffentlicht hätten, dass die CDU auf 37 Prozent kommt, wäre es schwieriger gewesen für die CDU, 37 Prozent zu bekommen.
»Deshalb bin ich auch dafür, dass man bis zuletzt Umfragen machen kann: Damit nicht nur Parteien oder Regierungen wissen, wie die Stimmung ist, sondern die Bevölkerung das transparent sieht und danach das Wahlverhalten ausrichten kann.«
Hermann Binkert
Wir haben halt gemessen, wie die Stimmung war, und ich halte es für logisch, dass die Leute, wenn sie eine solche Stimmung sehen, ihr Wahlverhalten daran ausrichten. Und sagen: Unter diesen Umständen will ich dieses oder jenes erreichen oder verhindern. Wenn es die Umfragen nicht gäbe, wäre diese Möglichkeit nicht da.
Sie halten es für einen demokratischen Effekt, dass man durch die Umfragen ein Gespür dafür bekommt, wie es ausgehen könnte, und das eigene Wahlverhalten entsprechend ändert?
Ja, das finde ich völlig richtig. Deshalb bin ich auch dafür, dass man bis zuletzt Umfragen machen kann: Damit nicht nur Parteien oder Regierungen wissen, wie die Stimmung ist, sondern die Bevölkerung das transparent sieht und danach das Wahlverhalten ausrichten kann. Dass das so drastisch ist wie in Sachsen-Anhalt jetzt, ist ein Ausnahmefall. Sonst ist es zum Beispiel eher so, dass man auf dieser Grundlage vielleicht eine kleine Partei als Koalitionspartner wählt, damit die über fünf Prozent kommt. Das hat dann nicht die Wirkung wie hier, wo von überall her, inklusive dem Lager der Nichtwähler, Leute sagten: Jetzt müssen wir schauen, dass die CDU stärkste Kraft wird.
Das erhöht aber natürlich erheblich den Anspruch an die Qualität solcher Umfragen. Wenn Sie die Macht haben, das Wahlverhalten von Menschen zu beeinflussen, ist es umso wichtiger, dass die Grundlage seriös ist.
Stimmt. Klar. Aber wir haben die Stimmung so gemessen. Und jedes Institut hat doch den Anspruch, möglichst nahe am Wahlergebnis zu sein. Es gibt doch niemanden, der sagt: Ich mache ein Umfrage-Ergebnis extra anders, um potentiell irgendwas damit zu erreichen. Aber wenn die Stimmung so ist, wie wir sie messen, halte ich es auch für falsch, zu sagen: Das könnte ja vielleicht eine Wirkung haben, deshalb müssen wir es irgendwie anders machen.
Sie lagen in der Vergangenheit häufig besser als die Konkurrenz, weil Sie die AfD stärker eingeschätzt haben. Gibt es bei INSA eine systematische Tendenz zugunsten der AfD, die Ihnen in der Vergangenheit geholfen, hier aber geschadet hat?
Das glaube ich nicht. Wir haben immer schon telefonisch und online erhoben. Infratest dimap macht das inzwischen auch – ich weiß nicht, ob das für den Effekt sorgt. Man hat ja eine Zeitlang auch so getan, als könnte man an der Stärke einer Partei in den Umfragen feststellen, wie ein Institut tickt. Wir erheben halt, wie die Zahlen sind. Ob eine Partei stärker ist oder schwächer, hat mit den Werten zu tun – nicht ob das besser ankommt.
„Das war nicht schön am Wochenende“
Aber angesichts der Ergebnisse der Wahl sahen Ihre Umfragen nicht gut aus.
Das war nicht schön am Wochenende. Wir wollen natürlich nicht so weit weg liegen. Aber ich bin überzeugt: Die Wähler im Land sind jetzt auch zufriedener mit dem Ergebnis.
Die anderen Institute haben es geschafft, näher dran zu sein.
Naja, die Forschungsgruppe Wahlen lag 7 Prozentpunkte unter dem CDU-Ergebnis, Infratest 9, wir 10. Das ist alles nicht so weit auseinander.
Der größte Unterschied zwischen Umfragen und Ergebnis war übrigens bei Bündnis 90 / Grüne. Wir haben da 8 Prozent gemessen, die Konkurrenz 9 – und am Ende ist die Partei bei 5,9 Prozent gelandet. Sie wurden rund 50 Prozent stärker gemessen, als sie waren. Das fällt hier, weil es ohnehin so wenig ist, nicht so ins Gewicht, aber es zeigt, welche kurzfristigen Änderungen es da im Wahlverhalten gab.
Das scheint ja ohnehin etwas zu sein, das die Wahlforschung in den ostdeutschen Bundesländern erschwert: Dass die Wähler den Parteien oder Lagern viel weniger treu bleiben.
Ja, die Bindungen sind nicht so ausgeprägt. Wenn linke Wähler CDU wählen, wäre das im Westen sehr ungewöhnlich. Im Osten kommt das vor.
Man konnte das zum Beispiel auch schon bei der Landtagswahl in Sachsen sehen, als Michael Kretschmer in Görlitz von Anhängern aller anderen Parteien gewählt wurden, die nicht die AfD vorne sehen wollten.
Das ist attraktiv für Wähler, dass sie erheblich mitentscheiden über den zukünftigen Ministerpräsidenten, indem sie dafür sorgen, dass er die stärkste Kraft ist.
„Ich habe meine politische Geschichte hinter mir“
Es ist vielleicht paradox, ausgerechnet einen Meinungsforscher das zu fragen, aber: Glauben Sie, dass Journalisten Umfragen zu viel Bedeutung beimessen und ihre Berichterstattung zu sehr davon beeinflussen lassen?
Nein, ich finde es richtig, darüber zu informieren. Aber auch hier ist eine neutrale Berichterstattung wichtig. Und als Meinungsforscher muss man dann damit leben, dass Umfragen dazu führen, dass man nicht recht hatte.
Immer wieder, und gerade nach einer solchen Diskrepanz zwischen Umfragen und Ergebnissen, wird Ihnen eine eigene politische Agenda unterstellt. Sie waren früher Mitglied der Werte-Union. Werden Ihre Umfragen von Ihren eigenen politischen Überzeugungen beeinflusst? Schadet es der Glaubwürdigkeit Ihres Institutes, wenn die Umfragen auch vor dem Hintergrund Ihrer eigenen politischen Positionen interpretiert werden?
Man kann seine Vergangenheit nicht abtun. Aber ich bin mit mir und dem Institut im Reinen. Wir bekommen Aufträge von allen Parteien im Bundestag und in den Landtagen. Das macht mich zufrieden. Die machen das nicht, weil sie gut finden, wo ich Parteimitglied war, sondern wegen guter Arbeit.
Ich habe meine eigene politische Geschichte hinter mir. In der Werte-Union war ich auch nie wirklich aktiv; aus der CDU bin ich 2014 ausgetreten; ich bin nur noch Mitglied in der Mittelstands-Union. Jetzt interessiert mich, das Wahlverhalten der Wähler zu messen und nachzuvollziehen.
32 Kommentare
Diese starken Abweichungen von Ergebnis und Prognose/Stimmungslage waren nicht nur in Sachsen-Anhalt zu sehen, sondern sind fast normal, wenn man viele Wahlen der letzten Jahre bis Jahrzehnte untersucht. Es scheinen hier also ein oder mehrere Verzerrungsfaktoren vorzuliegen.
Ein solcher Verzerrungsfaktor kann man mit den Stichworten Storytelling bzw. Aufmerksamkeitsökonomie kennzeichnen. Sowohl Meinungsforscher wie auch Journalisten bekommen mehr Beachtung (und mehr Umsatz), wenn sie eine schöne Story dem Publikum anbieten können. Hier ist es insbesondere die Story „Kopf-an-Kopf-Rennen“ sehr beliebt. Natürlich werden dazu keine Zahlen gefälscht, aber man kann sich vorstellen, dass Meinungsforscher bei den Korrekturen von Ausreißern unbewusst (möglicherweise auch nicht so ganz unbewusst) steuern.
Der Fehler bei den Journalisten ist dann noch, dass sie in ihrer Darstellung (anders als die Institute) fast vollständig darauf verzichten, die Bandbreiten aufzuzeigen, die jede Prognose/Stimmungslage nun mal hat. Eine Schwankung von 2 – 3 Prozentpunkten bei den Werten der einzelnen Parteien in beide Richtungen füren zu halbwegs realistischen Einschätzungen; aber leider, leider: Die schöne Story wird blas und die Aufmerksamkeit des Publikums geht zurück.
Dass Wähler anderer demokratischer Parteien die CDU gewählt haben, könnte erklären, dass die CDU von 27 (Umfrage) auf 37 Prozent (Wahl) gesprungen ist. Es kann aber nicht erklären, weshalb die AfD von 26 auf 21 abgesackt ist. Die Wahlbeteiligung war einen Prozentpunkt niedriger als vor 5 Jahren, es sind also nicht einfach besonders viele Nichtwähler dazu gekommen.
@erwinzk: Ja, das stimmt.
Man könnte es damit erklären, dass es auch potentielle AfD-Wähler gegeben hat, die die AfD zwar als starke Opposition wollten oder als kleineren Regierungspartner, aber nicht die AfD als stärkste Partei, und deshalb ebenfalls umgeschwenkt sind zur CDU.
Oder die angeblichen 26 Prozent für die AfD stimmten halt einfach nicht.
„So sind dann sehr viele junge Leute unter Ekel und mit Tränen in den Augen ins Wahllokal, um dort dann der CDU die Erststimme zu geben.“
Deckt sich grundsätzlich mit den Aussagen von Herrn Binkert.
Unpopular opinon meinerseits: Wahlpflicht, yeah!
ad #1:
„Hier ist es insbesondere die Story „Kopf-an-Kopf-Rennen“ sehr beliebt. Natürlich werden dazu keine Zahlen gefälscht, aber man kann sich vorstellen, dass Meinungsforscher bei den Korrekturen von Ausreißern unbewusst (möglicherweise auch nicht so ganz unbewusst) steuern.“
Solche „möglicherweise nicht ganz so unbewussten Korrekturen“ sind leicht mal in den Raum gestellt und lassen die Datenerhebung dann nebulös erscheinen. Mich würde nun interessieren, wie das technisch aussehen soll (Kenntnisse der empirischen Sozialforschung sind gegeben, also nur los).
Ein sogenannter Ausreißerwert läge z. B. vor, wenn bei einer (intervallskalierten) Variablen 99.999 Fälle zwischen 2,2 und 5,1 liegen, und nur ein Fall läge bei 8. Auch solche Ausreißer kann man nicht beliebig streichen, aber natürlich nach bestimmten, transparent gemachten Regeln. Aber wie soll ich mir das jetzt vorstellen, wenn man Personen fragt, welche Partei sie Sonntag wählen würde? Jede (kategoriale) Antwortausprägung wäre legitim, „weiß nicht“ und „unverständliche Antwort“ ebenfalls. Die Idee eines „Ausreißerwertes“ ist hier sinnlos. Wie sollen hier also Zahlen zugunsten einer guten Geschichte methodisch beschönigt worden sein (wenn wir nicht eine glatte Fälschung annehmen)?
[Es ist sicher nicht der Hauptaspekt des threads, aber eben der, der mich interessiert. :-) ]
Um was es hier bei meinen sehr vorsichtigen Andeutungen gehen könnte: Einfach mal bei Übermedien die Namen von bekannten Meinungsforschungsinstituten bzw. deren Chefs eintippen.
Auch Meinungsforscher müssen die Ergebnisse ihrer Algorithmen im Sinne einer mehr oder weniger plausiblen Heuristik korrigieren, um bessere Ergebnisse zu bekommen. Blos besser wofür? Für die bessere Prognose oder für die bessere Anpassung an die Wünsche der Auftraggeber? Natürlich kann man mit dieser Anpassungsheuristik keine Splitterpartei zur absoluten Mehrheit führen. Aber ein paar Prozentpunkte sind immer drin.
Der Herr Binkert versucht systematisch uns an der Nase herumzuführen:
Zuerst sagt er:
„Aber dann würde ich ja eine Prognose machen, dann würde ich selber in unseren ermittelten Zahlen herumpfuschen. Das machen wir nicht.“
Und dann heißt es:
„“Wir haben dafür eine Rückerinnerungsfrage drin, in der wir fragen, was die Befragten beim letzten Mal gewählt haben. Damit können wir gewichten.“
Ah ja, nicht „herumpfuschen“, nur „gewichten“ und das ausgerechnet mit der „Erinnerungsfrage“ von der die Wahlforschung seit gefühlter Ewigkeit weiß, dass ein Teil der Wähler schon am Tag nach der Wahl nicht mehr weiß, wen man gewählt hat.
Schönfärberisch ist die danach folgende Aussage:
„Wir haben es auch bei der Bundestagswahl gesehen, dass die Messung funktioniert – da waren wir am nächsten von allen Instituten am Ergebnis dran. Ich glaube wirklich, dass es in Sachsen-Anhalt eine Sondersituation war.“
Ich verstehe den Herrn so: Wenn die Zahlen passen ist die Methode gut, wenn sie nicht passen, liegt halt eine „Sondersituation“ vor. Wissenschaft ist das sicher nicht.
Auch ein weiteres Beispiel überzeugt nicht im geringsten:
„Jeder hat seine Lieblingsfußballmannschaft. Aber wenn es ins Finale geht und darum, dass nur zwei Mannschaften siegen können, dann stellen sich auch die Fans anderer Mannschaften hinter eine, die noch die Chance hat, siegen zu können.“
Es gibt nämlich auch die gegenteilige Reaktion: Ein Teil der Fans wendet sich dem Underdog zu und will es dem Favoriten (Bayern München z.B.) richtig heimzahlen. Für die Erklärung einer desaströsen Umfrage bringt das überhaupt nichts. Das weiß die Wahlforschung auch seit ca. 50 Jahren.
Ergebnis: INSA und alle anderen Institute ebenfalls haben ein miserables Produkt im Angebot, dass sie allerdings immer noch überteuert verkaufen können. Es erfüllt nur in wenigen Fällen seinen Zweck, Umtausch wird ausgeschlossen und Kostenerstattung kommt nicht in Frage. So ein Unternehmen möchte man gerne besitzen.
@ #7: Das Produkt ist super, nicht miserabel – Aus eben den Gründen, die Sie schon auflisten. Und es erfüllt doch einen Zweck, nämlich ein Ergebnis zu liefern, das man rumreichen und diskutieren kann.
Müsste man mal testen: Einfach jede Woche 100 Personen befragen, wen sie wählen würden und mal schauen, wie stark das Ergebnis von den renommierten Instituten abweicht.
50% Abweichung, sagt Binkert, sind ja noch okay. Denke, da kommt man sogar mit n<20 hin.
Dat kann der Azubi vom Schönenborn nebenbei machen und man sich so ne Menge Gebührengeld sparen.
Nachtrag, wegen Denkfehler:
Die 50% Abweichung bezogen sich bei Binkert auf den Vergleich zum tatsächlichen Ergebnis. Die größte Abweichung zwischen den einzelnen Instituten liegt bei 3%, relativ zum Ergebnis der einzelnen Parteien.
Hochgerechnet am Beispiel „Linke“ (INSA, 26.5. vs. Infratest, 27.5.) sind wir hier aber auch bei über 30%.
Selbst, wenn ich die CDU (FG Wahlen, 3.6. vs. INSA, 4.6.) nehme, sind es noch mehr als 10%.
Mit Konfidenzniveau 95 und 10% Fehlerspanne sollten also n<100 reichen, um ein genau so aussagekräftiges Ergebnis, wie renommierte Institute erhalten zu können.
Braucht man eigentlich eine bestimmte Qualifikation, um ein Wahlforschungsinstitut aufzumachen?
@Anderer Max
Die Größe des n wäre bei einer homogenen Bevölkerung nicht das Problem. Die Bevölkerung ist aber extrem heterogen. Das große Problem ist deshalb, die n Personen repräsentativ auszuwählen. Und da fangen die Probleme an, wenn vor allem Anhänger einer Partei nicht gerne an Umfragen teilnehmen, die der andern umso mehr. Oder Männer eher als Frauen usw. usf.
So schnell ist ein Bias drin. Deshalb braucht es am Ende die Korrekturrechnungen, um zum Beispiel den zu hohen Männeranteil in den Umfragen auszugleichen. Da würde ich keinem Institut unterstellen wollen, das nicht nach bestem Gewissen zu tun.
Desweiteren: Man braucht von jeder heterogenen Teilgruppe dann wenigstens 20, um solche Biases rausrechnen zu können.
An sich fand ich die Ergebnisse deshalb immer erstaunlich nahe an den Umfragen in den letzten Jahren. Teile die Beobachtung nicht, dass es allzu starke Abweichungen gegeben hätte.
Am Ende ist es aber klar, dass man das Ergebnis nie genau treffen wird. Allein das Wetter am Wahltag kann für einige Prozent verschieben sorgen, weil es die Psychologie der Unentschiedenen beeinflusst. Sonnenschein begünstigt die Regierung, Regen die Opposition…
(Das n=20 hatte ich aus dem ersten Kommentar gegriffen, ist für die gewünschten Abweichungen in der Tat zu niedrig, auch für Teilgruppen)
@#10 Sie schreiben:
“ Das große Problem ist deshalb, die n Personen repräsentativ auszuwählen.“
Die Umfragen vor den Wahlen werden in der Regel telephonisch durchgeführt, so viel ich weiß. Da gibt es nichts „auszuwählen“. Die Institute müssen so lange herumtelefonieren (lassen), bis man eine ausreichende Anzahl (ca. 1000) Antwortende gefunden hat. Kein Institut gibt bekannt, wie viele Anrufe sie tätigen musste. Danach muss dann irgendwie durch „gewichten“ eine Repräsentativität der Daten hergestellt werden. Und es muss berücksichtigt werden, dass die Auskunftsbereitschaft bei den Befragten durchaus unterschiedlich sein kann. Es muss nochmals „korrigiert“ werden, wie die Institute zugeben, nach eigenen Erfahrungen. In diese Korrekturen muss auch einfließen, ob die Aussagen der befragten überhaupt glaubwürdig sind. Leider ist das am schwierigsten zu kontrollieren. Und überhaupt nicht zu kontrollieren ist die Eigenart vieler Menschen, die nach der Methode verfahren: „Was kümmert mich mein Geschwätz von gestern“ (=was ich gestern am Telefon gesagt habe, was ich in 2 Wochen wählen werde).
Die Datengrundlage der Telefoninterviews ist leider so dramatisch schlecht, dass im Ergebnis die Kaffeesatzleserei auch kein schlechteres Ergebnis liefert. Dann schaut man zum Nachbarinstitut, dreht an dieser und jener Schraube und liefert ein Ergebnis, das einigermaßen plausibel erscheint und nicht zu sehr vom Vormonat (und den anderen Instituten) abweicht, es sei denn, man verfolgt eine unlautere Absicht.
Um bei meinem Vergleich von oben (#7) zu bleiben: Das Produkt ist so miserabel schlecht, weil der Rohstoff nichts taugt.
@ #10: „Da würde ich keinem Institut unterstellen wollen, das nicht nach bestem Gewissen zu tun.“
Ich auch nicht! Ich unterstelle den Instituten auch keine inhärente Manipulation oder sowas. Ich sage nur, dass man mit deutlich weniger Aufwand zu einem ähnlich aussagekräftigen Ergebnis kommen kann.
Und klar sind die Einwände korrekt, dass man eine repräsentative Auswahl treffen muss. In meiner Modellrechnung hatte ich daher auch Standardwerte für Konfidenz und Fehlerquote eingesetzt. Je unrepräsentativer die Auswahl, desto größer muss der Umfang der Stichprobe sein, um ein ähnlich aussagekräftiges Ergebnis zu haben.
@ #12: „Das Produkt ist so miserabel schlecht, weil der Rohstoff nichts taugt.“
Das Produkt ist nicht schlecht, dafür sind die Ergebnisse viel zu nah an am tatsächlichen Resultat. Außerdem verkauft sich das Produkt hervorragend.
Sehr interessante Diskussion. Was bisher noch zu wenig angesprochen wurde: die Interessenlage der Auftraggeber, bzw die Interessenlage des Instituts in der Öffentlichkeit als interessant wahrgenommen zu werden. Beide Faktoren verfälschen die Qualität, ohne dass man unterstellen muss,dass dies bewusst geschieht.
Auch finde ich es spannend, mal darüber nachzudenken, welche Grade von Repräsentativität denn überhaupt berechenbar sind. Wie kann ich nach einer Telefonumfrage, die wie beschrieben extrem problematisch ist, denn erkennen, das die gefundenen Zahlen ein hohes oder ein geringes Maß von Repräsentativität haben?
So richtig interessant wird diese Diskussion um den Beobachtungseffekt solcher Umfragen spätestens dann werden, wenn die Gewichtung der erhobenen Daten von KIs übernommen wird, wodurch die Voraussagen vermutlich besser aber nicht mehr nachvollziehbar werden.
Rein vom Prinzip her, wenn sich die Ergebnisse der Institute untereinander so wenig unterscheiden, benutzen die ähnliche Verfahren, die demnach den Sachverhalt ähnlich abbilden.
Das spricht ja erstmal nicht gegen das Verfahren.
Wenn die tatsächliche Wahl dann anders verläuft, ist das dann eher eine „selbstzerstörende Prophezeiung“. Analog zu: „Wenn wir weiter FCKW benutzen, geht die Ozon-Schicht kaputt.“
Da würde ich dem Interview zustimmen: „Sagen, was ist“, nicht „Sagen, was sein sollte“ oder „Sagen, was sein müsste“ oder „Etwas sagen, was nicht ganz stimmt, aber Leute motiviert, etwas zu tun, was ich gerne hätte“.
@12: ich wurde vor ein paar Jahren von einem Meinungsforschungsinstitut angerufen. Die stellen vorher ein paar grundlegende Fragen. Und als die Dame feststellte, dass ich zu der Bevölkerungsgruppe gehörte, von der sie schon genug befragt hatte, war Schluss mit dem Telefonat.
Ich glaube, die haben Statistiken von Bundesamt vorliegen, um die Umfrage so gut wie möglich repräsentativ zu gestalten. Ich bin statistisch nicht versiert genug, um einschätzen zu können, ob 1023 Leute dafür ausreichen.
@#17
Nähere Hinweise zum konkreten Verfahren kann man hier nachlesen: https://www.forschungsgruppe.de/Rund_um_die_Meinungsforschung/Methodik_Online-Umfragen/
Zu ergänzen wäre, dass eine „Gewichtung“ der Umfragewerte das mathematische Modell der Zufallsauswahl hinfällig machen, denn eine gewichtetes Ergebnis ist nicht mehr zufällig im mathematischen Sinne. Die Institute sehen darüber aber großzügig hinweg und begründen dies mit ihren Erfahrungswerten. Wie man bei der Sachsen-Anhalt sehen konnte, kann das aber völlig schief gehen.
An der Methode der telefonischen Befragung gibt es ebenfalls erhebliche Zweifel. Mehr dazu in diesem Wikipeia-Artikel: https://de.wikipedia.org/wiki/Sonntagsfrage
@15: wie sollte die KI das schaffen können, bessere Ergebnisse zu liefern?
@19: ich nehme an, unter Einsatz von einer oder mehrerer Blockchains ;)
Machine Learning wäre hier wahrscheinlich der zielführendere Ansatz.
Wie soll eine Maschine etwas lernen, dass die empirische Sozialforschung noch gar nicht verstanden hat. Ob auf einem Foto eine Katze ist, kann man als Mensch erkennen. Ob eine Prognose für eine Wahl richtig ist, kann man erst hinterher wissen. Warum sie falsch ist, darüber gibt es nur Spekulationen. Ich wüsste nicht, wie dieses nichtwissen der Sozialforschung umgangen werden könnte.
Aber eine lernende Maschine könnte nach Vorliegen der Wahlergebnisse durchprobieren, mit welchen Gewichtungen die Prognosen näher an den Ergebnissen gewesen wären. Es gibt doch mittlerweile glaube ich Beispiele für solche Algorithmen, die Vorhersagen erlauben aber kein Mensch mehr versteht, wie sie dazu kommen. Z.B. wenn anhand der Mediennutzung vorausgesagt werden kann, dass jemand demnächst krank werden wird.
Ob eine Prognose für eine Wahl richtig ist, kann man erst hinterher wissen.
Ja, und für bereits stattgefundene Wahlen ist bereits „hinterher“.
Für vergangene Wahlen habe ich die Umfragedaten und das richtige / tatsächliche Ergebnis. Damit füttere ich die Maschine. Und dann kann sie mir für neue Umfragedaten eine Prognose errechnen, basierend auf dem, was sie aus den alten Daten „gelernt“ hat. Und wenn die Datenmenge und -qualität ausreichend groß ist kann die Maschine damit möglicherweise sehr exakte Prognosen errechnen; von denen man natürlich erst nach der Wahl weiß, wie gut sie wirklich waren.
… WENN die Datenqualität …
… möglicherweise …
Sorry für das polemische Zitieren, aber durch diese Einschränkungen/Relativierungen wird der Inhalt Deiner Aussage natürlich schwer bezweifelbar.
KI kann meiner Einschätzung nach nur dann funktionieren, wenn es hinter den Abweichungen einen oder wenige Faktoren X gibt, die in systematischer Weise für die bisherigen Abweichungen gesorgt haben. Das würde ich stark bezweifeln. Ein Indiz für diesen Zweifel ist die Landtagswahl in Thüringen, die für die Wahlforschungsabweichungen im Rahmen blieb. Hier waren Linke und AfD die großen Gewinner. https://www.mdr.de/nachrichten/thueringen/landtagswahl/daten-landesergebnis100.html
Ich schrieb nicht über KI sondern Machine Learning. Und ja, das steht und fällt natürlich mit der Qualität (und auch Quantität) der verfügbaren Daten.
@12
Ja, „auswählen“ war nicht gut ausgedrückt. „erreichen“ trifft es besser, weil allgemeiner. Ansonsten scheinen wir uns über die Schwierigkeit so einer Umfrage weitestgehend einig, nur in der Bewertung des Endproduktes nicht.
Nachtrag zur Meinungsforschung:
Manfred Güllner hat inzwischen der FAZ ein Interview gegeben, wo er seine Einschätzung bezüglich der Abweichung zwischen den Umfrageergebnissen und dem tatsächlichen Wahlergebnis abgibt. Güllner glaubt nicht daran, dass es je ein Kopf-an-Kopf-Rennen zwischen CDU und AfD gegeben habe. Das beste Institut sei von einem Vorsprung von 7 Prozentpunkten ausgegangen, was zwar auch ziemlich ungenau war, aber nie als Kopf-an-Kopf-Rennen angesehen werden konnte.
Viele Medien hätten hingegen auf Civey gesetzt, denen Güllner schon länger keine guten Ergebnisse zutraut, weil sie auf Internet-Abstimmungen setzen. Diese könnten sehr gut von einer bestimmten Partei manipuliert werden.
Meine Meinung dazu: Die von Güllner als kritisch angesehen Vorgehensweisen müssen nicht unbedingt immer schlechtere Ergebnisse produzieren, als die herkömmlichen Verfahren. Allerdings können diese durchaus anfälliger sein für die Verzerrungsfaktoren, die ich im Kommentar #1 angedeutet habe.
Wie gesagt, n>100 bei Standardkonfidenz und -Fehlerspanne reicht aus um ähnlich zuverlässige Ergebnisse, wie rennomierte Institute zu erhalten. Jemand mit mehr Statistik-Background mag meiner Laien-Rechnung oben gerne widersprechen (bitte!!).
Das ist ja keine Blackbox, die ein Ergebnis ausspuckt von dem man nicht weiß, wie es zustande kam (wie es bei Machine Learning meist der Fall ist), sondern ein normiertes, transparentes Verfahren, das jeder anwenden kann.
Mich würden mal die Vergleiche zu Websites interessieren, die per einfachem Umfrage-Plugin auch die Sonntagsfrage stellen. Ich wette, die Abweichung zu den Instituten ist nicht größer, als die der rennomierten Institute untereinander.
Was durchaus die Frage aufwerfen kann, warum wir 28tausend Umfrage-Institute benötigen, wenn nicht aus kommunikativen Gründen.
Die Aussage mit dem n>100 stimmt nur, wenn die Stichprobe zufällig bestimmt wurde. Das war aber bei herkömmlichen Wahlumfragen noch nie gewährleistet und wird auch von Jahr zu Jahr schlechter. Auch neuere Verfahren kranken daran, dass eine Zufallsauswahl über Internet-Befragungen schwer vorstellbar ist.
Blackbox-Problem: Bei beiden Varianten müssen Zuordnungen bzw. Streichungen vorgenommen werden, deren Logik das Geschäftsgeheimnis der Institute ist. Also sind für alle (außer den Chefs der Institute für ihre eigenen Methoden), also für die komplette Öffentlichkeit, die Ergebnisse von Wahlumfragen vor dem Wahltag so, als ob sie aus einer Black-Box kommen.
@ #29: Aber warum soll uns das Geschäftsgeheimnis dieser Firmen denn interessieren, wenn das Ergebnis auch ohne die Maßnahmen in der Blackbox innerhalb der Standardabweichung liegt? Hat die Blackbox dann überhaupt eine Daseinsberechtigung? Kann man dann nicht einfach „grob über den Daumen peilen“ ohne Genauigkeitsverlust? (Ich weiß, sehr provokativ …)
Und na klar geht man von einer kompletten Zufallsverteilung der Teilnehmer aus. Wenn die nicht gegeben ist, muss die Stichprobengröße entsprechend vergrößert werden. Wie Sie im vorigen Beitrag ja auch schon schrieben, müssen sich die renommierten Institute ja auch Argumente gegen Civey vorbringen, in Ihrem Beispiel ist das die Manipulierbarkeit, die m. E. aber von der (viel größeren?) Stichprobengröße konterkariert wird.
Aber auch hier: Wenn das Ergebnis dauerhaft innerhalb der Abweichung liegt, die die Institute sowieso untereinander haben (Standardabweichung – weiß nicht ob das der richtige Begriff ist, sorry), wieso sollte man dann noch die Blackbox-Maßnahmen anwenden oder auf Manipulierbarkeit schielen? Sind dann nicht dennoch beide Verfahren gleichwertig anzusehen, weil sie sich innerhalb der gleichen Fehlermarge bewegen?
Das einzige langfristige Problem, das ich hier sehe ist das Abhandenkommen eines Standards und dass sich dadurch über einen längeren Zeitraum evtl. Fehler einschleichen, die letztenendes das Ergebnis so beeinflussen, dass es nicht mehr innerhalb der Standardabweichung liegt, die es gäbe, würde man diese Standards nach wie vor anwenden.
Ich weiß nicht, ob das nachvollziehbar ist, was ich sagen will, mit fehlt leider das Vokabular.
Wenn ich hier total falsch liege und intellektuelles Niveaulimbo betreibe liegt das einzig an meiner Inkompetenz und man teile es mir gerne mit!
Ich verstehe Sie schon und eigentlich sind wir nicht so weit auseinander. Das über den Daumen abschätzen geht meines Erachtens schon in Richtung Black-Box. So könnte beispielsweise eine der Daumen-Regeln lauten: CDU-Wähler geben ihr Wahlverhalten nicht so gerne preis wie Grünen-Wähler. Dann gibt man dem CDU-Anteil einen Aufschlag bzw. dem Grünen-Anteil einen Abschlag.
Hochgestochen könnte man hier von einer Heuristik sprechen, die sich langfristig bewährt hat. Angeblich ein Grund dafür, dass Nat Silver als einzigem die richtige Prognose in allen USA-Bundesstaaten 2008 gelungen ist. Leider für Silver hat das dann 8 Jahre später nicht mehr funktioniert. Die Heuristik hat nicht mehr gepasst; das Black-Box-Modell war veraltet. (Exkurs Ende)
Nicht zustimmen kann ich der Einschätzung, man könnte die Zufallsauswahl verbessern, in dem man mehr Leute befragt. Beispiele: Über Festnetz erreicht man oft nur ältere Leute mit Telefonbuch-Eintrag, mehr Anrufe – mehr Verzerrung (1) Civey erreicht mit mehr Umfragen und mehr Teilnehmern nur mehr Leute, die gerne an Umfragen teilnehmen.(2)
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.


Diese starken Abweichungen von Ergebnis und Prognose/Stimmungslage waren nicht nur in Sachsen-Anhalt zu sehen, sondern sind fast normal, wenn man viele Wahlen der letzten Jahre bis Jahrzehnte untersucht. Es scheinen hier also ein oder mehrere Verzerrungsfaktoren vorzuliegen.
Ein solcher Verzerrungsfaktor kann man mit den Stichworten Storytelling bzw. Aufmerksamkeitsökonomie kennzeichnen. Sowohl Meinungsforscher wie auch Journalisten bekommen mehr Beachtung (und mehr Umsatz), wenn sie eine schöne Story dem Publikum anbieten können. Hier ist es insbesondere die Story „Kopf-an-Kopf-Rennen“ sehr beliebt. Natürlich werden dazu keine Zahlen gefälscht, aber man kann sich vorstellen, dass Meinungsforscher bei den Korrekturen von Ausreißern unbewusst (möglicherweise auch nicht so ganz unbewusst) steuern.
Der Fehler bei den Journalisten ist dann noch, dass sie in ihrer Darstellung (anders als die Institute) fast vollständig darauf verzichten, die Bandbreiten aufzuzeigen, die jede Prognose/Stimmungslage nun mal hat. Eine Schwankung von 2 – 3 Prozentpunkten bei den Werten der einzelnen Parteien in beide Richtungen füren zu halbwegs realistischen Einschätzungen; aber leider, leider: Die schöne Story wird blas und die Aufmerksamkeit des Publikums geht zurück.
Dass Wähler anderer demokratischer Parteien die CDU gewählt haben, könnte erklären, dass die CDU von 27 (Umfrage) auf 37 Prozent (Wahl) gesprungen ist. Es kann aber nicht erklären, weshalb die AfD von 26 auf 21 abgesackt ist. Die Wahlbeteiligung war einen Prozentpunkt niedriger als vor 5 Jahren, es sind also nicht einfach besonders viele Nichtwähler dazu gekommen.
@erwinzk: Ja, das stimmt.
Man könnte es damit erklären, dass es auch potentielle AfD-Wähler gegeben hat, die die AfD zwar als starke Opposition wollten oder als kleineren Regierungspartner, aber nicht die AfD als stärkste Partei, und deshalb ebenfalls umgeschwenkt sind zur CDU.
Oder die angeblichen 26 Prozent für die AfD stimmten halt einfach nicht.
Hier ein Leserbrief auf Fefes Blog zum Thema:
https://blog.fefe.de/?ts=9e432058
„So sind dann sehr viele junge Leute unter Ekel und mit Tränen in den Augen ins Wahllokal, um dort dann der CDU die Erststimme zu geben.“
Deckt sich grundsätzlich mit den Aussagen von Herrn Binkert.
Unpopular opinon meinerseits: Wahlpflicht, yeah!
ad #1:
„Hier ist es insbesondere die Story „Kopf-an-Kopf-Rennen“ sehr beliebt. Natürlich werden dazu keine Zahlen gefälscht, aber man kann sich vorstellen, dass Meinungsforscher bei den Korrekturen von Ausreißern unbewusst (möglicherweise auch nicht so ganz unbewusst) steuern.“
Solche „möglicherweise nicht ganz so unbewussten Korrekturen“ sind leicht mal in den Raum gestellt und lassen die Datenerhebung dann nebulös erscheinen. Mich würde nun interessieren, wie das technisch aussehen soll (Kenntnisse der empirischen Sozialforschung sind gegeben, also nur los).
Ein sogenannter Ausreißerwert läge z. B. vor, wenn bei einer (intervallskalierten) Variablen 99.999 Fälle zwischen 2,2 und 5,1 liegen, und nur ein Fall läge bei 8. Auch solche Ausreißer kann man nicht beliebig streichen, aber natürlich nach bestimmten, transparent gemachten Regeln. Aber wie soll ich mir das jetzt vorstellen, wenn man Personen fragt, welche Partei sie Sonntag wählen würde? Jede (kategoriale) Antwortausprägung wäre legitim, „weiß nicht“ und „unverständliche Antwort“ ebenfalls. Die Idee eines „Ausreißerwertes“ ist hier sinnlos. Wie sollen hier also Zahlen zugunsten einer guten Geschichte methodisch beschönigt worden sein (wenn wir nicht eine glatte Fälschung annehmen)?
[Es ist sicher nicht der Hauptaspekt des threads, aber eben der, der mich interessiert. :-) ]
Um was es hier bei meinen sehr vorsichtigen Andeutungen gehen könnte: Einfach mal bei Übermedien die Namen von bekannten Meinungsforschungsinstituten bzw. deren Chefs eintippen.
Auch Meinungsforscher müssen die Ergebnisse ihrer Algorithmen im Sinne einer mehr oder weniger plausiblen Heuristik korrigieren, um bessere Ergebnisse zu bekommen. Blos besser wofür? Für die bessere Prognose oder für die bessere Anpassung an die Wünsche der Auftraggeber? Natürlich kann man mit dieser Anpassungsheuristik keine Splitterpartei zur absoluten Mehrheit führen. Aber ein paar Prozentpunkte sind immer drin.
Der Herr Binkert versucht systematisch uns an der Nase herumzuführen:
Zuerst sagt er:
„Aber dann würde ich ja eine Prognose machen, dann würde ich selber in unseren ermittelten Zahlen herumpfuschen. Das machen wir nicht.“
Und dann heißt es:
„“Wir haben dafür eine Rückerinnerungsfrage drin, in der wir fragen, was die Befragten beim letzten Mal gewählt haben. Damit können wir gewichten.“
Ah ja, nicht „herumpfuschen“, nur „gewichten“ und das ausgerechnet mit der „Erinnerungsfrage“ von der die Wahlforschung seit gefühlter Ewigkeit weiß, dass ein Teil der Wähler schon am Tag nach der Wahl nicht mehr weiß, wen man gewählt hat.
Schönfärberisch ist die danach folgende Aussage:
„Wir haben es auch bei der Bundestagswahl gesehen, dass die Messung funktioniert – da waren wir am nächsten von allen Instituten am Ergebnis dran. Ich glaube wirklich, dass es in Sachsen-Anhalt eine Sondersituation war.“
Ich verstehe den Herrn so: Wenn die Zahlen passen ist die Methode gut, wenn sie nicht passen, liegt halt eine „Sondersituation“ vor. Wissenschaft ist das sicher nicht.
Auch ein weiteres Beispiel überzeugt nicht im geringsten:
„Jeder hat seine Lieblingsfußballmannschaft. Aber wenn es ins Finale geht und darum, dass nur zwei Mannschaften siegen können, dann stellen sich auch die Fans anderer Mannschaften hinter eine, die noch die Chance hat, siegen zu können.“
Es gibt nämlich auch die gegenteilige Reaktion: Ein Teil der Fans wendet sich dem Underdog zu und will es dem Favoriten (Bayern München z.B.) richtig heimzahlen. Für die Erklärung einer desaströsen Umfrage bringt das überhaupt nichts. Das weiß die Wahlforschung auch seit ca. 50 Jahren.
Ergebnis: INSA und alle anderen Institute ebenfalls haben ein miserables Produkt im Angebot, dass sie allerdings immer noch überteuert verkaufen können. Es erfüllt nur in wenigen Fällen seinen Zweck, Umtausch wird ausgeschlossen und Kostenerstattung kommt nicht in Frage. So ein Unternehmen möchte man gerne besitzen.
@ #7: Das Produkt ist super, nicht miserabel – Aus eben den Gründen, die Sie schon auflisten. Und es erfüllt doch einen Zweck, nämlich ein Ergebnis zu liefern, das man rumreichen und diskutieren kann.
Müsste man mal testen: Einfach jede Woche 100 Personen befragen, wen sie wählen würden und mal schauen, wie stark das Ergebnis von den renommierten Instituten abweicht.
50% Abweichung, sagt Binkert, sind ja noch okay. Denke, da kommt man sogar mit n<20 hin.
Dat kann der Azubi vom Schönenborn nebenbei machen und man sich so ne Menge Gebührengeld sparen.
Nachtrag, wegen Denkfehler:
Die 50% Abweichung bezogen sich bei Binkert auf den Vergleich zum tatsächlichen Ergebnis. Die größte Abweichung zwischen den einzelnen Instituten liegt bei 3%, relativ zum Ergebnis der einzelnen Parteien.
Hochgerechnet am Beispiel „Linke“ (INSA, 26.5. vs. Infratest, 27.5.) sind wir hier aber auch bei über 30%.
Selbst, wenn ich die CDU (FG Wahlen, 3.6. vs. INSA, 4.6.) nehme, sind es noch mehr als 10%.
Mit Konfidenzniveau 95 und 10% Fehlerspanne sollten also n<100 reichen, um ein genau so aussagekräftiges Ergebnis, wie renommierte Institute erhalten zu können.
Braucht man eigentlich eine bestimmte Qualifikation, um ein Wahlforschungsinstitut aufzumachen?
@Anderer Max
Die Größe des n wäre bei einer homogenen Bevölkerung nicht das Problem. Die Bevölkerung ist aber extrem heterogen. Das große Problem ist deshalb, die n Personen repräsentativ auszuwählen. Und da fangen die Probleme an, wenn vor allem Anhänger einer Partei nicht gerne an Umfragen teilnehmen, die der andern umso mehr. Oder Männer eher als Frauen usw. usf.
So schnell ist ein Bias drin. Deshalb braucht es am Ende die Korrekturrechnungen, um zum Beispiel den zu hohen Männeranteil in den Umfragen auszugleichen. Da würde ich keinem Institut unterstellen wollen, das nicht nach bestem Gewissen zu tun.
Desweiteren: Man braucht von jeder heterogenen Teilgruppe dann wenigstens 20, um solche Biases rausrechnen zu können.
An sich fand ich die Ergebnisse deshalb immer erstaunlich nahe an den Umfragen in den letzten Jahren. Teile die Beobachtung nicht, dass es allzu starke Abweichungen gegeben hätte.
Am Ende ist es aber klar, dass man das Ergebnis nie genau treffen wird. Allein das Wetter am Wahltag kann für einige Prozent verschieben sorgen, weil es die Psychologie der Unentschiedenen beeinflusst. Sonnenschein begünstigt die Regierung, Regen die Opposition…
(Das n=20 hatte ich aus dem ersten Kommentar gegriffen, ist für die gewünschten Abweichungen in der Tat zu niedrig, auch für Teilgruppen)
@#10 Sie schreiben:
“ Das große Problem ist deshalb, die n Personen repräsentativ auszuwählen.“
Die Umfragen vor den Wahlen werden in der Regel telephonisch durchgeführt, so viel ich weiß. Da gibt es nichts „auszuwählen“. Die Institute müssen so lange herumtelefonieren (lassen), bis man eine ausreichende Anzahl (ca. 1000) Antwortende gefunden hat. Kein Institut gibt bekannt, wie viele Anrufe sie tätigen musste. Danach muss dann irgendwie durch „gewichten“ eine Repräsentativität der Daten hergestellt werden. Und es muss berücksichtigt werden, dass die Auskunftsbereitschaft bei den Befragten durchaus unterschiedlich sein kann. Es muss nochmals „korrigiert“ werden, wie die Institute zugeben, nach eigenen Erfahrungen. In diese Korrekturen muss auch einfließen, ob die Aussagen der befragten überhaupt glaubwürdig sind. Leider ist das am schwierigsten zu kontrollieren. Und überhaupt nicht zu kontrollieren ist die Eigenart vieler Menschen, die nach der Methode verfahren: „Was kümmert mich mein Geschwätz von gestern“ (=was ich gestern am Telefon gesagt habe, was ich in 2 Wochen wählen werde).
Die Datengrundlage der Telefoninterviews ist leider so dramatisch schlecht, dass im Ergebnis die Kaffeesatzleserei auch kein schlechteres Ergebnis liefert. Dann schaut man zum Nachbarinstitut, dreht an dieser und jener Schraube und liefert ein Ergebnis, das einigermaßen plausibel erscheint und nicht zu sehr vom Vormonat (und den anderen Instituten) abweicht, es sei denn, man verfolgt eine unlautere Absicht.
Um bei meinem Vergleich von oben (#7) zu bleiben: Das Produkt ist so miserabel schlecht, weil der Rohstoff nichts taugt.
@ #10: „Da würde ich keinem Institut unterstellen wollen, das nicht nach bestem Gewissen zu tun.“
Ich auch nicht! Ich unterstelle den Instituten auch keine inhärente Manipulation oder sowas. Ich sage nur, dass man mit deutlich weniger Aufwand zu einem ähnlich aussagekräftigen Ergebnis kommen kann.
Und klar sind die Einwände korrekt, dass man eine repräsentative Auswahl treffen muss. In meiner Modellrechnung hatte ich daher auch Standardwerte für Konfidenz und Fehlerquote eingesetzt. Je unrepräsentativer die Auswahl, desto größer muss der Umfang der Stichprobe sein, um ein ähnlich aussagekräftiges Ergebnis zu haben.
@ #12: „Das Produkt ist so miserabel schlecht, weil der Rohstoff nichts taugt.“
Das Produkt ist nicht schlecht, dafür sind die Ergebnisse viel zu nah an am tatsächlichen Resultat. Außerdem verkauft sich das Produkt hervorragend.
Sehr interessante Diskussion. Was bisher noch zu wenig angesprochen wurde: die Interessenlage der Auftraggeber, bzw die Interessenlage des Instituts in der Öffentlichkeit als interessant wahrgenommen zu werden. Beide Faktoren verfälschen die Qualität, ohne dass man unterstellen muss,dass dies bewusst geschieht.
Auch finde ich es spannend, mal darüber nachzudenken, welche Grade von Repräsentativität denn überhaupt berechenbar sind. Wie kann ich nach einer Telefonumfrage, die wie beschrieben extrem problematisch ist, denn erkennen, das die gefundenen Zahlen ein hohes oder ein geringes Maß von Repräsentativität haben?
So richtig interessant wird diese Diskussion um den Beobachtungseffekt solcher Umfragen spätestens dann werden, wenn die Gewichtung der erhobenen Daten von KIs übernommen wird, wodurch die Voraussagen vermutlich besser aber nicht mehr nachvollziehbar werden.
Rein vom Prinzip her, wenn sich die Ergebnisse der Institute untereinander so wenig unterscheiden, benutzen die ähnliche Verfahren, die demnach den Sachverhalt ähnlich abbilden.
Das spricht ja erstmal nicht gegen das Verfahren.
Wenn die tatsächliche Wahl dann anders verläuft, ist das dann eher eine „selbstzerstörende Prophezeiung“. Analog zu: „Wenn wir weiter FCKW benutzen, geht die Ozon-Schicht kaputt.“
Da würde ich dem Interview zustimmen: „Sagen, was ist“, nicht „Sagen, was sein sollte“ oder „Sagen, was sein müsste“ oder „Etwas sagen, was nicht ganz stimmt, aber Leute motiviert, etwas zu tun, was ich gerne hätte“.
@12: ich wurde vor ein paar Jahren von einem Meinungsforschungsinstitut angerufen. Die stellen vorher ein paar grundlegende Fragen. Und als die Dame feststellte, dass ich zu der Bevölkerungsgruppe gehörte, von der sie schon genug befragt hatte, war Schluss mit dem Telefonat.
Ich glaube, die haben Statistiken von Bundesamt vorliegen, um die Umfrage so gut wie möglich repräsentativ zu gestalten. Ich bin statistisch nicht versiert genug, um einschätzen zu können, ob 1023 Leute dafür ausreichen.
@#17
Nähere Hinweise zum konkreten Verfahren kann man hier nachlesen:
https://www.forschungsgruppe.de/Rund_um_die_Meinungsforschung/Methodik_Online-Umfragen/
Zu ergänzen wäre, dass eine „Gewichtung“ der Umfragewerte das mathematische Modell der Zufallsauswahl hinfällig machen, denn eine gewichtetes Ergebnis ist nicht mehr zufällig im mathematischen Sinne. Die Institute sehen darüber aber großzügig hinweg und begründen dies mit ihren Erfahrungswerten. Wie man bei der Sachsen-Anhalt sehen konnte, kann das aber völlig schief gehen.
An der Methode der telefonischen Befragung gibt es ebenfalls erhebliche Zweifel. Mehr dazu in diesem Wikipeia-Artikel:
https://de.wikipedia.org/wiki/Sonntagsfrage
@15: wie sollte die KI das schaffen können, bessere Ergebnisse zu liefern?
@19: ich nehme an, unter Einsatz von einer oder mehrerer Blockchains ;)
Machine Learning wäre hier wahrscheinlich der zielführendere Ansatz.
Wie soll eine Maschine etwas lernen, dass die empirische Sozialforschung noch gar nicht verstanden hat. Ob auf einem Foto eine Katze ist, kann man als Mensch erkennen. Ob eine Prognose für eine Wahl richtig ist, kann man erst hinterher wissen. Warum sie falsch ist, darüber gibt es nur Spekulationen. Ich wüsste nicht, wie dieses nichtwissen der Sozialforschung umgangen werden könnte.
Aber eine lernende Maschine könnte nach Vorliegen der Wahlergebnisse durchprobieren, mit welchen Gewichtungen die Prognosen näher an den Ergebnissen gewesen wären. Es gibt doch mittlerweile glaube ich Beispiele für solche Algorithmen, die Vorhersagen erlauben aber kein Mensch mehr versteht, wie sie dazu kommen. Z.B. wenn anhand der Mediennutzung vorausgesagt werden kann, dass jemand demnächst krank werden wird.
Ja, und für bereits stattgefundene Wahlen ist bereits „hinterher“.
Für vergangene Wahlen habe ich die Umfragedaten und das richtige / tatsächliche Ergebnis. Damit füttere ich die Maschine. Und dann kann sie mir für neue Umfragedaten eine Prognose errechnen, basierend auf dem, was sie aus den alten Daten „gelernt“ hat. Und wenn die Datenmenge und -qualität ausreichend groß ist kann die Maschine damit möglicherweise sehr exakte Prognosen errechnen; von denen man natürlich erst nach der Wahl weiß, wie gut sie wirklich waren.
… WENN die Datenqualität …
… möglicherweise …
Sorry für das polemische Zitieren, aber durch diese Einschränkungen/Relativierungen wird der Inhalt Deiner Aussage natürlich schwer bezweifelbar.
KI kann meiner Einschätzung nach nur dann funktionieren, wenn es hinter den Abweichungen einen oder wenige Faktoren X gibt, die in systematischer Weise für die bisherigen Abweichungen gesorgt haben. Das würde ich stark bezweifeln. Ein Indiz für diesen Zweifel ist die Landtagswahl in Thüringen, die für die Wahlforschungsabweichungen im Rahmen blieb. Hier waren Linke und AfD die großen Gewinner. https://www.mdr.de/nachrichten/thueringen/landtagswahl/daten-landesergebnis100.html
Ich schrieb nicht über KI sondern Machine Learning. Und ja, das steht und fällt natürlich mit der Qualität (und auch Quantität) der verfügbaren Daten.
@12
Ja, „auswählen“ war nicht gut ausgedrückt. „erreichen“ trifft es besser, weil allgemeiner. Ansonsten scheinen wir uns über die Schwierigkeit so einer Umfrage weitestgehend einig, nur in der Bewertung des Endproduktes nicht.
Nachtrag zur Meinungsforschung:
Manfred Güllner hat inzwischen der FAZ ein Interview gegeben, wo er seine Einschätzung bezüglich der Abweichung zwischen den Umfrageergebnissen und dem tatsächlichen Wahlergebnis abgibt. Güllner glaubt nicht daran, dass es je ein Kopf-an-Kopf-Rennen zwischen CDU und AfD gegeben habe. Das beste Institut sei von einem Vorsprung von 7 Prozentpunkten ausgegangen, was zwar auch ziemlich ungenau war, aber nie als Kopf-an-Kopf-Rennen angesehen werden konnte.
Viele Medien hätten hingegen auf Civey gesetzt, denen Güllner schon länger keine guten Ergebnisse zutraut, weil sie auf Internet-Abstimmungen setzen. Diese könnten sehr gut von einer bestimmten Partei manipuliert werden.
Meine Meinung dazu: Die von Güllner als kritisch angesehen Vorgehensweisen müssen nicht unbedingt immer schlechtere Ergebnisse produzieren, als die herkömmlichen Verfahren. Allerdings können diese durchaus anfälliger sein für die Verzerrungsfaktoren, die ich im Kommentar #1 angedeutet habe.
Wie gesagt, n>100 bei Standardkonfidenz und -Fehlerspanne reicht aus um ähnlich zuverlässige Ergebnisse, wie rennomierte Institute zu erhalten. Jemand mit mehr Statistik-Background mag meiner Laien-Rechnung oben gerne widersprechen (bitte!!).
Das ist ja keine Blackbox, die ein Ergebnis ausspuckt von dem man nicht weiß, wie es zustande kam (wie es bei Machine Learning meist der Fall ist), sondern ein normiertes, transparentes Verfahren, das jeder anwenden kann.
Mich würden mal die Vergleiche zu Websites interessieren, die per einfachem Umfrage-Plugin auch die Sonntagsfrage stellen. Ich wette, die Abweichung zu den Instituten ist nicht größer, als die der rennomierten Institute untereinander.
Was durchaus die Frage aufwerfen kann, warum wir 28tausend Umfrage-Institute benötigen, wenn nicht aus kommunikativen Gründen.
Die Aussage mit dem n>100 stimmt nur, wenn die Stichprobe zufällig bestimmt wurde. Das war aber bei herkömmlichen Wahlumfragen noch nie gewährleistet und wird auch von Jahr zu Jahr schlechter. Auch neuere Verfahren kranken daran, dass eine Zufallsauswahl über Internet-Befragungen schwer vorstellbar ist.
Blackbox-Problem: Bei beiden Varianten müssen Zuordnungen bzw. Streichungen vorgenommen werden, deren Logik das Geschäftsgeheimnis der Institute ist. Also sind für alle (außer den Chefs der Institute für ihre eigenen Methoden), also für die komplette Öffentlichkeit, die Ergebnisse von Wahlumfragen vor dem Wahltag so, als ob sie aus einer Black-Box kommen.
@ #29: Aber warum soll uns das Geschäftsgeheimnis dieser Firmen denn interessieren, wenn das Ergebnis auch ohne die Maßnahmen in der Blackbox innerhalb der Standardabweichung liegt? Hat die Blackbox dann überhaupt eine Daseinsberechtigung? Kann man dann nicht einfach „grob über den Daumen peilen“ ohne Genauigkeitsverlust? (Ich weiß, sehr provokativ …)
Und na klar geht man von einer kompletten Zufallsverteilung der Teilnehmer aus. Wenn die nicht gegeben ist, muss die Stichprobengröße entsprechend vergrößert werden. Wie Sie im vorigen Beitrag ja auch schon schrieben, müssen sich die renommierten Institute ja auch Argumente gegen Civey vorbringen, in Ihrem Beispiel ist das die Manipulierbarkeit, die m. E. aber von der (viel größeren?) Stichprobengröße konterkariert wird.
Aber auch hier: Wenn das Ergebnis dauerhaft innerhalb der Abweichung liegt, die die Institute sowieso untereinander haben (Standardabweichung – weiß nicht ob das der richtige Begriff ist, sorry), wieso sollte man dann noch die Blackbox-Maßnahmen anwenden oder auf Manipulierbarkeit schielen? Sind dann nicht dennoch beide Verfahren gleichwertig anzusehen, weil sie sich innerhalb der gleichen Fehlermarge bewegen?
Das einzige langfristige Problem, das ich hier sehe ist das Abhandenkommen eines Standards und dass sich dadurch über einen längeren Zeitraum evtl. Fehler einschleichen, die letztenendes das Ergebnis so beeinflussen, dass es nicht mehr innerhalb der Standardabweichung liegt, die es gäbe, würde man diese Standards nach wie vor anwenden.
Ich weiß nicht, ob das nachvollziehbar ist, was ich sagen will, mit fehlt leider das Vokabular.
Wenn ich hier total falsch liege und intellektuelles Niveaulimbo betreibe liegt das einzig an meiner Inkompetenz und man teile es mir gerne mit!
Ich verstehe Sie schon und eigentlich sind wir nicht so weit auseinander. Das über den Daumen abschätzen geht meines Erachtens schon in Richtung Black-Box. So könnte beispielsweise eine der Daumen-Regeln lauten: CDU-Wähler geben ihr Wahlverhalten nicht so gerne preis wie Grünen-Wähler. Dann gibt man dem CDU-Anteil einen Aufschlag bzw. dem Grünen-Anteil einen Abschlag.
Hochgestochen könnte man hier von einer Heuristik sprechen, die sich langfristig bewährt hat. Angeblich ein Grund dafür, dass Nat Silver als einzigem die richtige Prognose in allen USA-Bundesstaaten 2008 gelungen ist. Leider für Silver hat das dann 8 Jahre später nicht mehr funktioniert. Die Heuristik hat nicht mehr gepasst; das Black-Box-Modell war veraltet. (Exkurs Ende)
Nicht zustimmen kann ich der Einschätzung, man könnte die Zufallsauswahl verbessern, in dem man mehr Leute befragt. Beispiele: Über Festnetz erreicht man oft nur ältere Leute mit Telefonbuch-Eintrag, mehr Anrufe – mehr Verzerrung (1) Civey erreicht mit mehr Umfragen und mehr Teilnehmern nur mehr Leute, die gerne an Umfragen teilnehmen.(2)
Verstanden! Danke für’s Feedback!